
Table of contents
- Introduction
- The merge data function and its arguments
- Merging data using command line
- Merging data using the GUI
Introduction
Large-scale assessments are often international comparative studies. Any analysis aiming at comparing countries would require repeating over and over the same analysis using data from a different country every time and then assemble the results obtained from all countries to compare them. Such procedure may not be optimal or even convenient. It would be much more convenient to add data from all countries together and then perform the analysis by country (or groups within every country, if needed. This would require first merging the countries data together.
Another reason one would need to merge data is because these studies collect data from different respondent – students, their teachers, school principals, parents and, in some cases, school ICT coordinators. A researcher may be interested, for example, in student achievement by the age or qualification of their teachers. Or, in the students being bullied by the type of area (urban or rural) where their school is located. In these cases one or more variables are located in the student data, and another set of variables is located in the teacher or school principal data. This would require that these data sets are merged for every country before merging all countries of interest together and perform the analysis. Merging the data sets from different respondents may look like an easy task, but in reality it may become really complex and depends on the design of the study in scope. Consider the first example (merging students with their teachers) using TIMSS Grade 4 data. TIMSS does not draw a separate sample of teachers. Instead, it samples intact classes within each sampled school and the teachers in the sample are only the teachers who teach the sampled students. When merging the data from students and teachers, we need to make sure that the proper link between them is established, i.e. every student is linked only to the teacher who teaches them, and no other. This kind of merge can become even more complex with TIMSS grade 8 data where every student has separate mathematics and science teachers. To make things even more complicated, in some countries students within a class are divided into groups and these groups are taught by multiple different mathematics and science teachers which makes the linking even more complicated. More complex scenarios may exist as well. It is important to make the proper link between the students and their parents, teachers and school principals when merging data from multiple different respondents. On top of everything else, in some studies other than TIMSS (ICCS and ICILS) students and teachers cannot be merged because of their sampling design. Each study has its own unique design.
This is what the lsa.merge.data function does – each study sampling design is taken into account when the function merges the data from different respondents. If an analyst requests merging file combination which is not possible for a particular study data, the function will stop and throw an error message to prevent wrongdoing. The function will also take care to maintain the variable properties like class, variable and value labels. Thus, we strongly recommend using the lsa.merge.data function for this task to avoid mistakes which at the end will affect the computations done in an analysis. Using means different than the lsa.merge.data function is on your own risk.
Note that the function works only with studies where the files for each cycle are provided per country, per respondent type (e.g. student, teacher, etc.). These are all supported studies so far, except for PISA. In every cycle PISA provides its files per respondent type and each file contains the data for all countries in each of the files. This, along with the file naming convention which changes in every cycle, does not permit finding a reliable approach towards merging their data.
The merge data function and its arguments
The lsa.merge.data function has the following arguments:
inp.folder– Folder containing the data sets. The data sets must be .RData, produced bylsa.convert.data.file.types– What file types (i.e. respondents) shall be merged?ISO– Vector containing character ISO codes of the countries’ data files to include in the merged file.out.file– Full path to the file the data shall be stored in. The object stored in the file will have the same name.
Notes:
- The function merges files from studies where the files are per country and respondent type (e.g. student, school, teacher). That is, all studies except PISA.
- The
inp.folderspecifies the path to the folder containing the.RDatafiles produced bylsa.convert.data. The folder must contain only files for a single study, single cycle and single population (e.g. TIMSS 2015 grade 4 or TIMSS 2015 grade 8, but not both), or mode of administration (e.g. either PIRLS 2016 or ePIRLS 2016, but not both; or TIMSS 2019 or TIMSS 2019 Bridge, but not both). All files in the input folder must be exported with the same option (TRUEorFALSE) of themissing.to.NAargument of thelsa.convert.datafunction. If input folder is not provided to the argument, the working folder (getwd()) will be used. - The folder must contain only files for a single study, single cycle and single population (e.g. TIMSS 2015, grade 4). All files in the input folder must be exported with the same option (TRUE or FALSE) of the missing.to.NA argument of the
lsa.convert.datafunction. If input folder is not provided to the argument, the working folder (getwd()) will be used. - The folder passed to the
inp.folderargument must contain files only for one study, cycle and population. Otherwise the function will stop with an error message. This is implemented like this to keep the folder structure clean and avoid accidental mistakes. Prefer anout.filedifferent thaninp.folderfor the same reason. - The
file.typesis a list of the respondent types as component names and their variables as elements to be merged. The file type names are three-character codes, the first three characters of the corresponding file names. The elements are vectors of upper case variable names, NULL takes all variables in the corresponding file. For example, in TIMSS “asg” will merge only student-level data from grade 4,c(asg, atg)will merge the student-level and teacher-level data from grade 4,c(bsg, btm)will merge student-level and mathematics teacher-level data from grade 8. If a merge is not possible by the study design, the function will stop with an error. - The
ISOis a character vector specifying the countries whose data shall be merged. The elements of the vector are the fourth, fifth and sixth characters in the file names. For example,c("aus", "swe", "svn")will merge the data from Australia, Sweden and Slovenia for the file types specified infile.types. The three-letter ISO codes for each country can be found in the user guide for the study in scope. For example, the ISO codes of the countries participating in PIRLS 2016 can be found in its user guide on pages 52-54. If file for specific country does not exist in theinp.folder, a warning will be issued. If theISOargument is missing, the files for all countries in the folder will be merged for the specifiedfile.types. - The
out.filemust contain full path (including the .RData extension, if missing, it will be added) to the output file (i.e. the file containing merged data). The file contains object with the same name and has a class extensionlsa.data. It has additional attributefile.typeshowing data from which respondents is available after the merging has been done. For example, merging the student-level data with teacher-level data in TIMSS grade 4 will assign “std.bckg.tch.bckg” to this attribute. The object has two additional attributes: study name (study) and study cycle (cycle). The object in the.RDatafile is keyed on the country ID variable. If output folder is not provided, the merged file will be saved in the working folder (getwd()) asmerged_data.RData. - TIMSS Longitudinal has two points of administration with the same sample of schools and, respectively, students. The teachers however, are not necessarily the same teachers in both administrations. When grade 4 teacher data is merged to student data, there are two sets of mathematics and science weights – one for the first year and one for the second year of administration. For grade 8, mathematics and science teachers have to be merged separately to student data, each having their own weights for the first and second year of administration. When analyses are performed, the first available weight is chosen as default. Student questionnaire items are available as two separate sets, one per year of administration. It is up to the analyst to choose the proper combination of items and weights for a particular analysis. For more details on the structure of the TIMSS Longitudinal database, see the TIMSS 2023 Longitudinal User Guide for the International Databse.
Merging data using command line
As a first example, we will merge the PIRLS 2016 student questionnaire files from Australia and Slovenia (Slovenia, not Slovakia!) which we converted in the previous step. In RStudio execute the following syntax:
lsa.merge.data(inp.folder = "C:/temp", ISO = c("aus", "svn"),
file.types = list(asg = NULL),
out.file = "C:/temp/merged/PIRLS_2016_ASG_AUS_SVN.RData")
The inp.folder argument points to the folder where we have saved the converted files in the previous step. The ISO argument takes a character vector with the countries three-letter ISO codes (these are the fourth, fifth and sixth characters in the file names). If you wish to merge the files from all countries available in the folder, simply omit this argument. The out.file argument specifies where to save the merged file. Again, it is advisable to keep the things clean and save the file in a folder different than inp.folder.
The file.types argument is more complicated. It must be passed as a list where each component is a file type abbreviation (first to third character in the file names) and takes a value. In PIRLS 2016 the “asg” abbreviation stands for student background questionnaire data. The way it is passed in the call from above (asg = NULL), NULL stands for “take all variables in the files for that file type”. What if we want to select only certain variables to be merged, say student sex (ASBG01), the number of books at home (ASBG04), and how much students enjoy reading (ASBR06E)? Then instead of NULL we need to pass a character vector against asg in the argument. The calling syntax will look like this:
lsa.merge.data(inp.folder = "C:/temp", ISO = c("aus", "svn"),
file.types = list(asg = c("ASBG01", "ASBG04", "ASBR06E")),
out.file = "C:/temp/merged/PIRLS_2016_ASG_AUS_SVN.RData")
Note that although none of the identification, tracking and weight variables, as well as the PV names are included in the vector of variable names for the asg, they will be added to the merged file automatically, you don’t need to worry about this. This applies to all file types being merge. We can make a more complex example merging all variables from the PIRLS 2016 student and teacher files for Australia and Slovenia (again, Slovenia, not Slovakia!) like this:
lsa.merge.data(inp.folder = "C:/temp", ISO = c("aus", "svn"),
file.types = list(asg = NULL, atg = NULL),
out.file = "C:/temp/merged/PIRLS_2016_ASG_ATG_AUS_SVN.RData")
And, if we want to merge just some of the variables in both file types, we can do it like this:
lsa.merge.data(inp.folder = "C:/temp", ISO = c("aus", "svn"),
file.types = list(asg = c("ASBG01", "ASBG04", "ASBR06E"), atg = c("ATBG05BF", "ATBG05BG", "ATBG05BH")),
out.file = "C:/temp/merged/PIRLS_2016_ASG_ATG_AUS_SVN.RData")
Merging data using the GUI
To start the RALSA user interface, execute the following command in RStudio:
ralsaGUI()
When the GUI opens in your browser, select Data preparation > Merge data from the menu on the left. When navigated to the Merge data section in the GUI, click on the Choose source folder button. Navigate to the folder containing the converted .RData files for the study (say PIRLS 2016). Select the folder containing the data in the left panel of the folder choose dialog box. The available .RData files in the folder are displayed in the right panel:
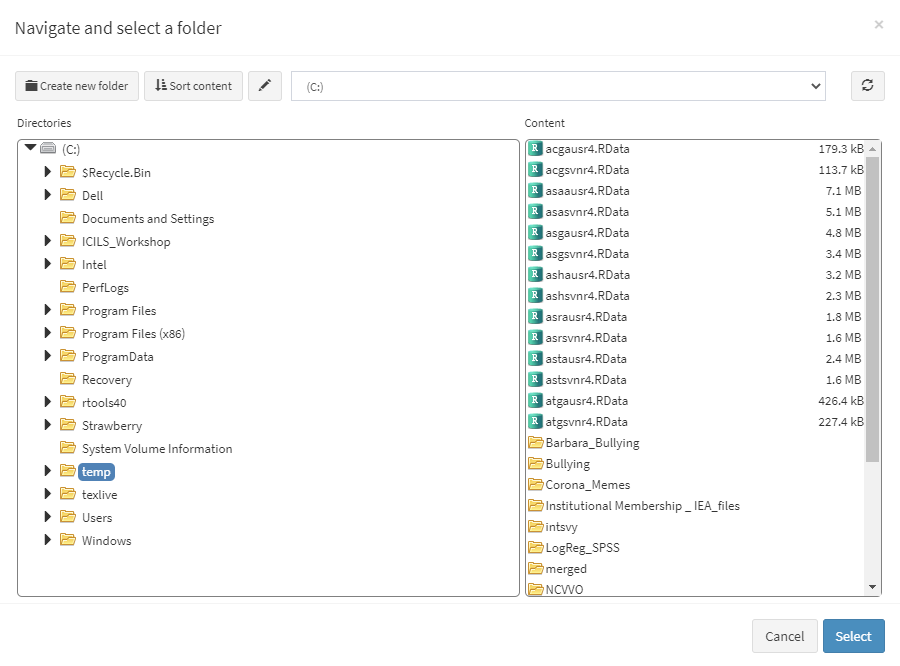
After you confirm by pressing Select, you will see the following screen:
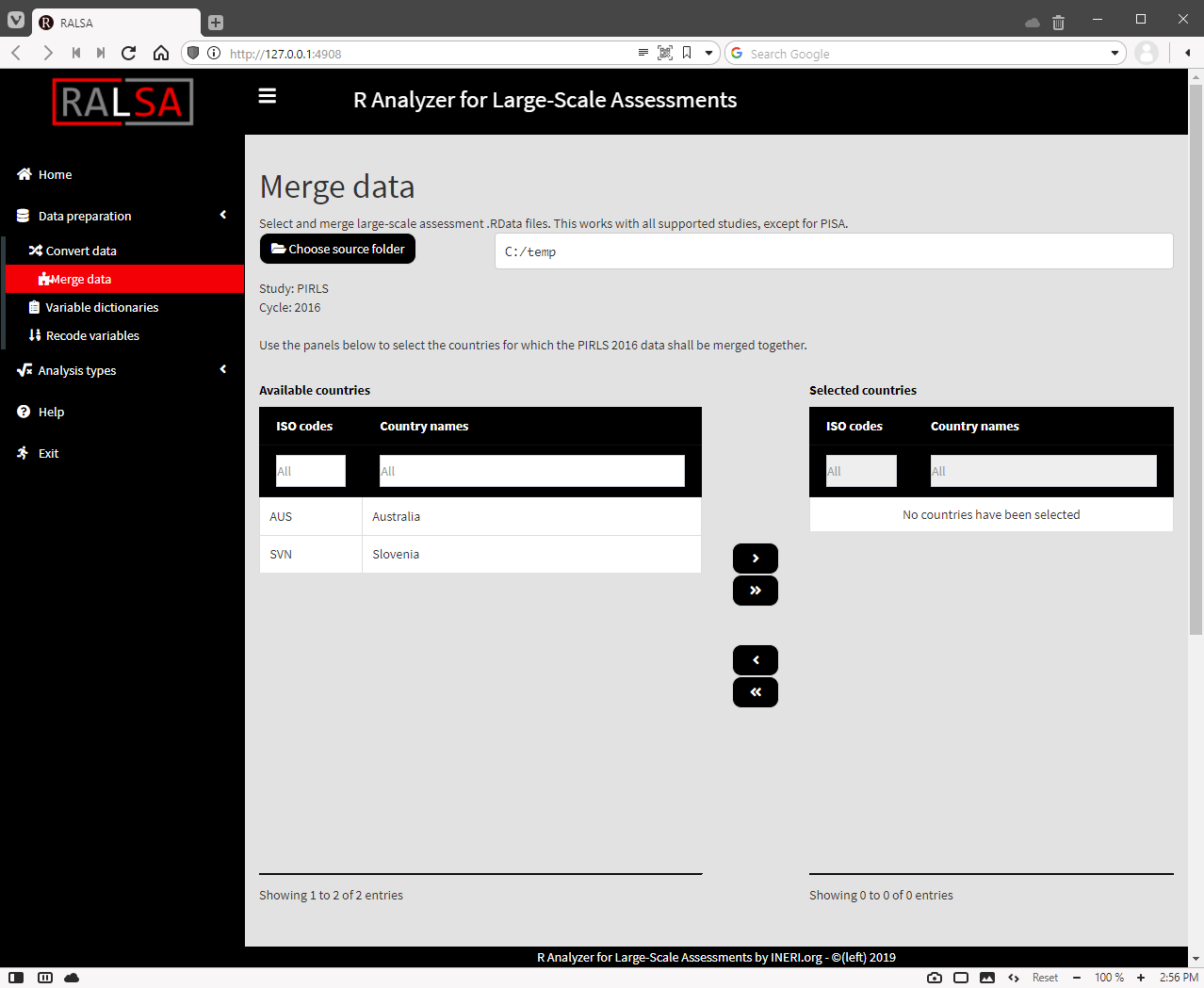
In the previous example we have converted just two countries – Australia and Slovenia (not Slovakia!). If more countries’ .RData files are located in the source folder, they will be displayed as well. Use the mouse to select and the single and double arrow buttons to move the countries between the lists of Available countries and Selected countries. The single arrow buttons can be used to select and move individual countries between the two panels. The double arrow buttons can be used to move all countries between the two panels, even if none of them are selected. Lets select both Australia and Slovenia (again, Slovenia, not Slovakia!). A set of multiple checkboxes for the file respondent file types found in the folder will appear under the panels, one per respondent file type:

You can select more than one file type to merge. If a merge combination is not possible (this will depend on the study sampling design, see the user guide and technical report for a particular study), a warning message will be issued. For this particular example, we will merge student and teacher background data sets. So check the “(ASG) Student background” and “(ATG) Teacher background” checkboxes. Once you do this another two panels will appear below:
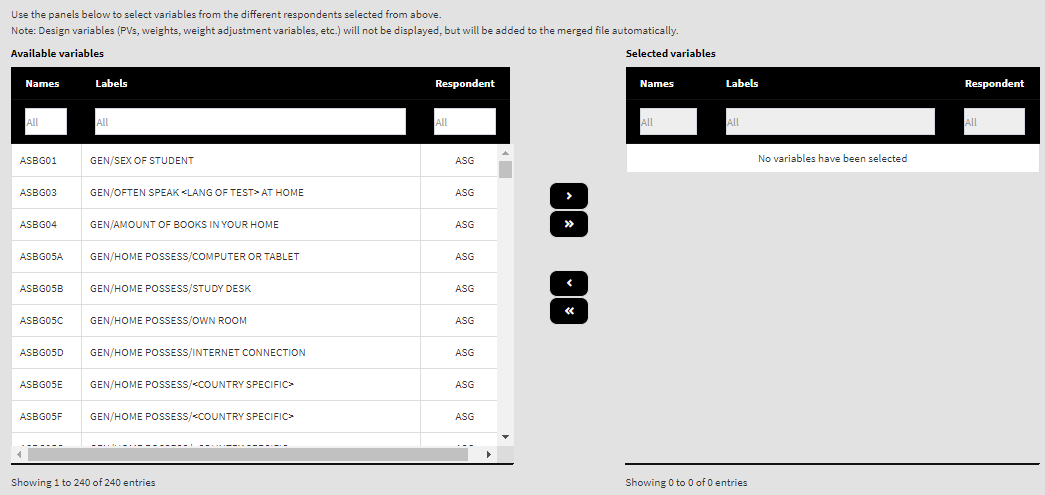
The last column in each panel shows which respondent type from above a variable belongs to. Use the mouse to select individual variables and the single arrow buttons to move them from the list of available variables to the list of selected variables and vice versa. Use the double arrow buttons to select all or no variables. You can use the filter boxes on the top of the panels to find the needed variables quickly. For this example, let’s select the same variables we selected in the last example when using the command line option (asg = c("ASBG01", "ASBG04", "ASBR06E"), atg = c("ATBG05BF", "ATBG05BG", "ATBG05BH")). Please note that all identification, tracking, and design variables (sampling, weighting and PVs) will be added to the merged file automatically. Once there are any variables in the Selected variables panel, the Define merged file name button will appear:
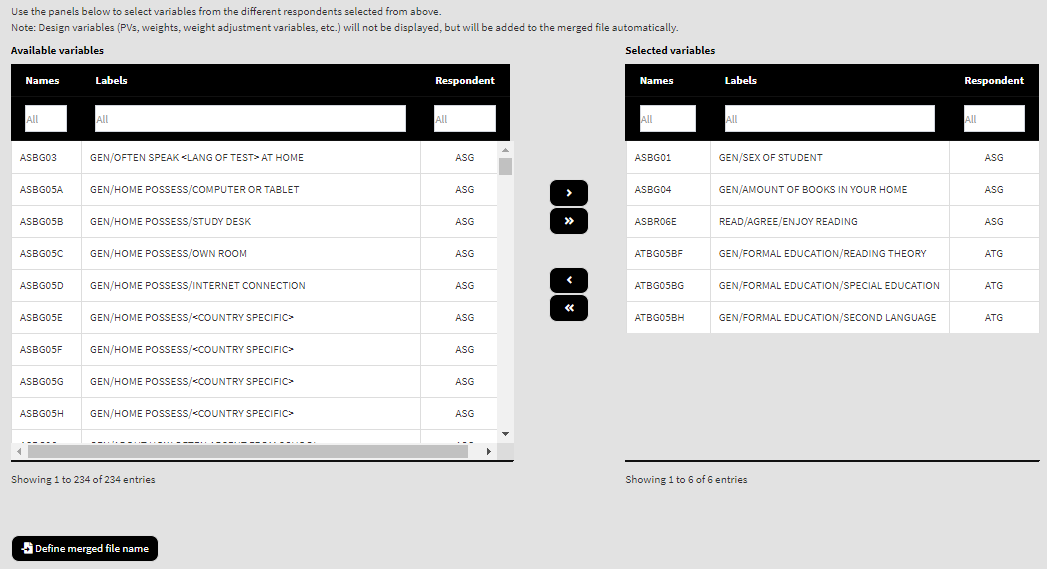
Press on the Define merged file name button, navigate to the folder you want to save the merged file and define the desired file name. Let’s save it under “C:/temp/merged/PIRLS_2016_ASG_ATG_AUS_SVN.RData”. When you do so, the calling syntax and the Execute syntax button will appear underneath:
Press the Execute syntax button. The syntax will be executed and all the operations will be displayed in the console window at the bottom of the screen. It will be updated on every step:
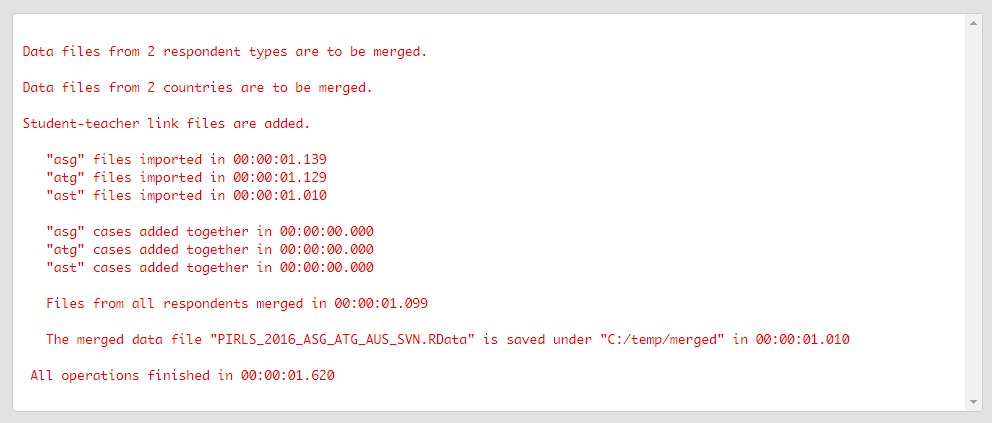
When all operations are done, a pop-up message will appear on the screen to inform you.