
Table of contents
- Introduction
- The data conversion function and its arguments
- Converting the SPSS data
- Convert PISA 2012 and earlier TXT files
Introduction
Data from large-scale assessments are provided in SPSS, SAS and TXT (in case of PISA prior its 2015 cycle) file formats (to obtain the files, see the links here). Various contributed R packages which import SPSS and SAS file formats, like foreign and haven, for example. Different functions in the initially loaded in R packages can read TXT delimited files, like read.delim, read.delim2 from the utils package, or functions in other contributed packages like readr or data.table, for example. However, all of these available functions have different implementation of the methods used to import data and the type of object resulting from the import, and this matters for the further computations (data preparation or analysis). It is, thus, difficult to predict how a user will import the data and what the result will be. In addition, it is much more convenient to have the data in native .RData format with a standardized structure to operate on. This is why this function to convert the data in .RData format is needed.
The lsa.convert.data function converts the data from SPSS file formats from IEA studies and PISA (2015 and later cycles) and TXT (in case of PISA prior its 2015 cycle) file formats into .RData files. In doing so, it adds some properties to the objects stored in these files, so that other functions (data preparation or analysis) in RALSA know what to do further with it when passed to them.
RALSA adds a new method to the print function from the base package to print lsa.data properties in the console – (study, cycle, respondent type, number of countries, key – country ID, and if the variables have user-defined missing values) and a preview of the data. The printing method for lsa.data is available only in command line mode.
The lsa.select.countries.PISA function allows the analyst to select countries for analysis from a converted PISA file and save it as a new file or object in memory. The PISA data files come with all countries per respondent inside. This may be rather cumbersome for the analyst who does not need to analyze all countries data in a file.
A few important notes:
- Do not modify any of the source SPSS or TXT (and .sps) files before converting them. Download the files, unpack the archives and do not change their names or content.
- You don’t need to convert the files for any further (data preparation or analysis) operations. Convert them once, then use the converted files.
- You will see the “IEA-like” phrase further down in the presentation. This means that the files are provided per cycle, country and respondent type, as opposed to the case where the files are provided for all countries together per study and cycle (as PISA does). Studies not operated by IEA, but using the same file structure are, for example TALIS and TALIS 3S.
The data conversion function, the lsa.data printing method, and the select PISA countries function and their arguments
The lsa.convert.data function has the following arguments:
inp.folder– The folder containing the IEA-like SPSS data files or text ASCII files and .sps import files for OECD PISA data from cycles prior to 2015 (see the details). If blank, the working directory (getwd()) is used.PISApre15– When converting PISA files, set toTRUEif the input files are from PISA cycles prior 2015 (ASCII text format with .sps control files) or toFALSE(default) if they are in SPSS .sav format, as in the case of IEA studies and the like and OECD PISA 2015 or later. Ignored if the input folder contains IEA-like studies.ISO– Vector containing character ISO codes of the countries’ data files to convert (e.g.ISO = c("aus", "svn")). If none of the files contain the specified ISO codes in their names, the codes are ignored and a warning is shown. Ignored when converting PISA files (both for cycles prior 2015 and 2015 and later). This argument is case-insensitive, i.e. the ISO codes can be passed as lower- or upper-case.missing.to.NA– Should the user-defined missing values be recoded toNA? IfTRUE, all user-defined missing values from the SPSS files (or specified in the OECD PISA import syntax files) are all imported asNA. IfFALSE(default), they are converted to valid values and the missing codes are assigned to an attribute missings for each variable.out.folder– Path to the folder where the converted files will be stored. If blank, same as theinp.folder, and if theinp.folderis missing as well, this will begetwd().
Related with the lsa.convert.data function is the printing method for lsa.data objects loaded in the memory. When the command (or simply the name of the object) is invoked, the print R command checks if the object is of class lsa.objects and, if yes, prints a structured output containing the study name, cycle, respondent type(s), total number of countries, key, if the data has user-defined missing values or not, and a snippet of the data. The following arguments can be passed to the print function:
x–lsa.dataobject.col.nums– Which columns to print, positions by number.
The lsa.select.countries.PISA function has the following arguments:
data.file– Converted PISA data file to select countries’ data from. Either this one ordata.objectmust be provided, but not both. See details.data.object– PISA object in memory to filter. Either this one ordata.filemust be provided, but not both. See details.cnt.names– Character vector containing the names of the countries, as they exist in the data, which should stay in the PISA exported file or object in memory.output.file– Full path to the file with the filtered countries’ data to be written on disk. If not provided, the PISA object will be written to memory.
Notes:
- IEA studies, as well as OECD TALIS and some conducted by other organizations, provide their data in SPSS
.savformat with same or very similar structure: one file per country and type of respondent (e.g. school principal, student, teacher, etc.) per population. For IEA studies and OECD TALIS use theISOargument to specify the countries’ three-letter ISO codes whose data is to be converted. The three-letter ISO codes for each country can be found in the user guide for the study in scope. For example, the ISO codes of the countries participating in PIRLS 2016 can be found in its user guide on pages 52-54. To convert the files from all countries in the downloaded data from IEA studies and OECD TALIS, simply omit theISOargument. Cycles of OECD PISA prior to 2015, on the other hand, do not provide SPSS.savor other binary files, but ASCII text files, accompanied with SPSS syntax (.sps) files that are used to import the text files into SPSS. These files are per each type of respondent containing all countries’ data. Thelsa.convert.datafunction converts the data from either source assuring that the structure of the output.RDatafiles is the same, although the structure of the input files is different (SPSS binary files vs. ASCII text files plus import.spsfiles). The data from PISA 2015 and later, on the other hand, is provided in SPSS format (all countries in one file per type of respondent). Thus, thePISApre15argument needs to be specified asTRUEwhen converting data sets from PISA prior to its 2015 cycle. The default for thePISApre15argument isFALSEwhich means that the function expects to find IEA-like SPSS binary files per country and type of respondent in the directory ininp.folderor OECD PISA 2015 (or later) SPSS.savfiles. IfPISApre15 = TRUEand country codes are provided toISO, they will be ignored because PISA files contain data from all countries together. - The files to be converted must be in a folder on their own, from a single study, single cycle and single population. In case of OECD PISA prior 2015, the folder must contain both the ASCII text files and the SPSS .sps import syntax files. If the folder contains data sets from more than one study or cycle, the operation will break with error messages.
- If the path for the
inp.folderargument is not specified, the function will search for files in the working directory (i.e. as returned bygetwd()). If folder path for the the out.folder is not specified, it will take the one from the inp.folder and the files will be stored there. If both the inp.folder and out.folder arguments are missing, the directory from getwd() will be used to search, convert and store files. - If
missing.to.NAis set toTRUE, all user-defined missing values from the SPSS will be imported as NA which is R’s only kind of missing value. This will be the most often case when analyzing these data since the reason why the response is missing will be irrelevant most of the times. However, if it is needed to know why the reasons for missing responses, as when analyzing achievement items (i.e. not administered vs. omitted or not reached), the argument shall be set toFALSE(default for this argument) which will convert all user-defined missing values as valid ones. - When downloading the .sps files (ASCII text and control .sps) for OECD PISA files prior to the 2015 cycle (say https://www.oecd.org/pisa/pisaproducts/pisa2009database-downloadabledata.htm), save them without changing their names and without modifying the file contents. The function will look for the files as they were named originally.
- Different studies and cycles define the “I don’t know” (or similar) category of discrete variables in different ways – either as a valid or missing value. The
lsa.convert.datafunction sets all such or similar codes to missing value. If this has to be changed, thelsa.recode.varscan be used as well (also seelsa.vars.dict).
Converting the SPSS data
The lsa.convert.data converts SPSS data into native .RData format from the following studies:
- CivED;
- ICCS;
- ICILS;
- RLII;
- PIRLS (including PIRLS Literacy and ePIRLS);
- TIMSS (including TIMSS Numeracy, eTIMSS);
- TiPi (TIMSS and PIRLS joint study);
- TIMSS Advanced;
- SITES;
- TEDS-M;
- PISA (2015 and later cycles);
- TALIS;
- TALIS Starting Strong Survey (a.k.a. TALIS 3S); and
- REDS.
There is a difference between PISA (2015 and later cycles) and the rest of the studies (IEA-like) in the list above. All except PISA provide the files per cycle, country, and respondent type (e.g. school principal, teacher, student, or parent). For example, these are the SPSS files for Slovenia from PIRLS 2016 (to see the file and variable naming conventions, and the description of the data base files, please refer to Chapter 4 of the PIRLS 2016 User Guide):
acgsvnr4.sav– school principal questionnaire responses;asasvnr4.sav– student responses on the achievement items;asgsvnr4.sav– student questionnaire responses, include the PVs too;ashsvnr4.sav– parental questionnaire responses;asrsvnr4.sav– achievement items reliability;astsvnr4.sav– student-teacher linkage files;atgsvnr4.sav– teacher questionnaire responses.
This division in separate files makes it very convenient to operate with the files and merge custom data sets for the analysis, i.e. merging only countries and respondent types needed.
SPSS data files from PISA 2015 and later cycles are organized in a different way. OECD provides the data per cycle and respondent type. Each respondent type file contains data from all countries participating in the cycle. For example, these are the files from PISA 2018 cycle:
CY07_MSU_SCH_QQQ.sav– school principal questionnaire responses;CY07_MSU_STU_COG.sav– student responses on the achievement items;CY07_MSU_STU_QQQ.sav– student questionnaire responses, include the PVs too;CY07_MSU_STU_TIM.sav– student achievement items timing log;CY07_MSU_TCH_QQQ.sav– teacher questionnaire responsesCY07_VNM_STU_COG.sav– student responses on the achievement items, Vietnam only;CY07_VNM_STU_PVS.sav– PVs for Vietnam only.
It is important to note that the file types and their naming differ from one PISA cycle to another. However, the lsa.convert.data function can handle these differences out of the box and automatically recognize the study name and the data files’ properties to convert them successfully.
Converting SPSS files using command line
As an example, we will convert PIRLS 2016 data. In RStudio execute the following syntax:
lsa.convert.data(inp.folder = "E:/IDB/PIRLS_2016_IDB/Data/PIRLS",
ISO = c("aus", "svn"),
out.folder = "C:/temp")
This will convert the PIRLS 2016 data for Australia and Slovenia (Slovenia, not Slovakia!). It will take all files available for these two countries in the inp.folder for that cycle and will store them under the out.folder. If the inp.folder folder contains data from more than one study and/or cycle or more than one population, the function will stop with an error. If the out.folder is the same as inp.folder, the function will convert the data anyway, but will display a warning at the end. These two are intentional – to keep the folders and the file structure clean and tidy, always have the SPSS data from one study/cycle/population only stored in a folder, and always choose a folder for the converted .RData files that is different from the source SPSS files.
RStudio will output log messages like this in the console.
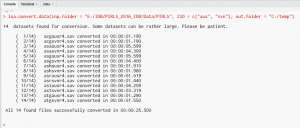
What if we want to convert files from all PIRLS 2016 countries in the inp.folder? We can simply omit the ISO argument (i.e. not passing any country ISO codes) in the function call. This will tell the lsa.convert.data function to take the SPSS data files from all countries stored in the inp.folder and convert it:
lsa.convert.data(inp.folder = "E:/IDB/PIRLS_2016_IDB/Data/PIRLS",
out.folder = "C:/temp")
Note that the execution time will depend on the number of files per respondent type in the data base, the size of individual file types and the number of countries. However, with the IEA-like data bases, the conversion process goes rather quick. For example, converting the entire PIRLS 2016 data base (the main PIRLS, not ePIRLS or prePIRLS) has data from 57 countries (seven files per country), and takes about 11 minutes to convert. If you don’t need to convert the data from all countries, but just the ones you will need in your analyses, use the ISO argument as shown above.
What about the SPSS files from PISA 2015 and later cycles? The routine is the same. However, as mentioned in the beginning, the SPSS files for a PISA cycle are provided for all countries within a file type. As a consequence, you will not be able to convert data from these data bases for individual countries, but whole files. If you try to pass the ISO argument to the call, it will be ignored. The syntax will look like this:
lsa.convert.data(inp.folder = "E:/IDB/PISA_2018_IDB/Data",
out.folder = "C:/temp")
Messages similar to the previous conversion of PIRLS 2016 data base will be printed to the console as well. Note that because the individual files have a rather complex structure, they contain data from all countries and a large number of variables, the conversion of PISA SPSS files can take really long time. The entire PISA 2015 data base, for example takes around 5.5 hours on a computer with Intel Core i7-7500U CPU and 16GB of RAM. This can be rather frustrating. You can leave the computer work on this over night and have the converted data files in the morning.
The file can be loaded in the memory and printed in the console by just passing the name of the loaded object. To load a converted data file, say the student file for Slovenia:
load("C:/temp/asgsvnr4.RData")
The load function will read the file an will load the asgsvnr4 object from it in the memory. We can print the object by simply passing its name:
asgsvnr4
The print function from the base package will find the appropriate method for lsa.data and will produce the following output on screen:
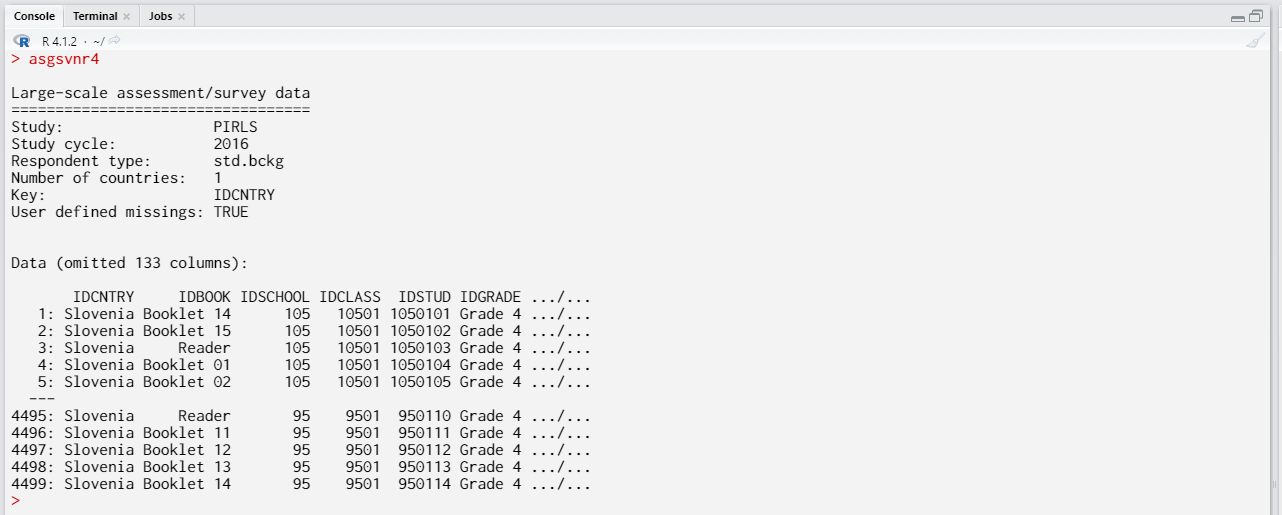
Note that by default the firsts six columns will be printed. If we need to, we can print different columns depending on our interest by suplying column numbers:
print(x = asgsvnr4, col.nums = c(20:25))
The corresponding output looks like this:
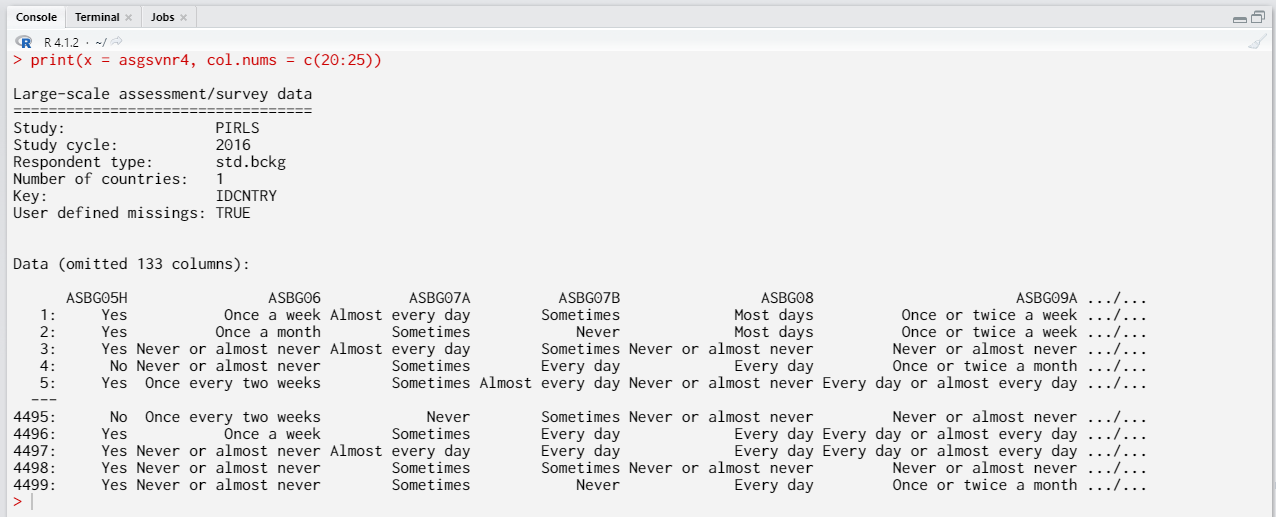
Converting SPSS files using the GUI
To start the RALSA user interface, execute the following command in RStudio:
ralsaGUI()
When the GUI opens in your browser, select Data preparation > Convert data from the menu on the left. When navigated to the Convert data section in the GUI, click on the Choose source folder. Navigate to the folder containing the SPSS files for the study (say PIRLS 2016). Select the folder containing the data in the left panel of the folder choose dialog box. The available SPSS files in the folder are displayed in the right panel:
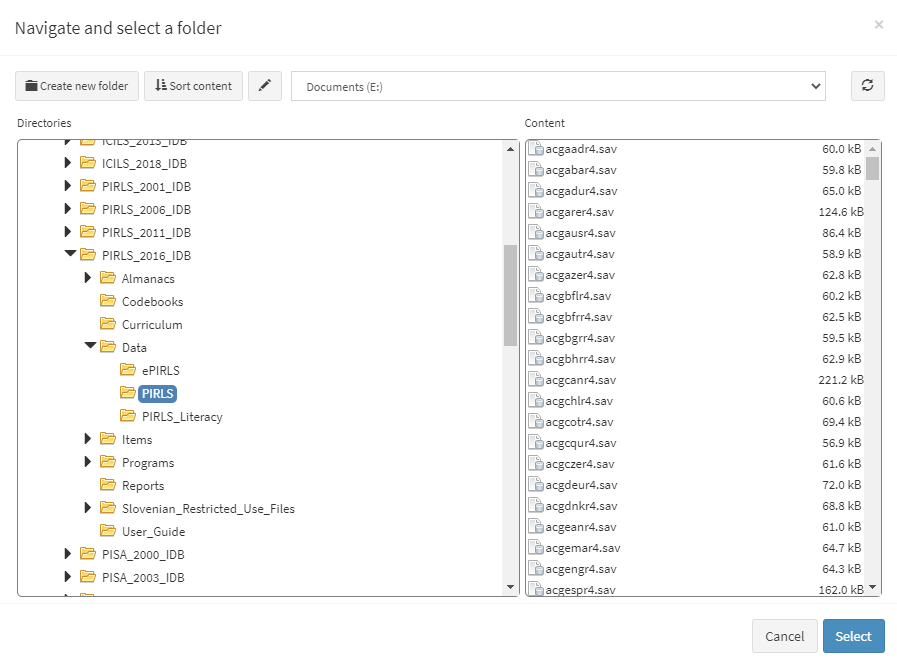
After you confirm by pressing Select, you will see the following screen:
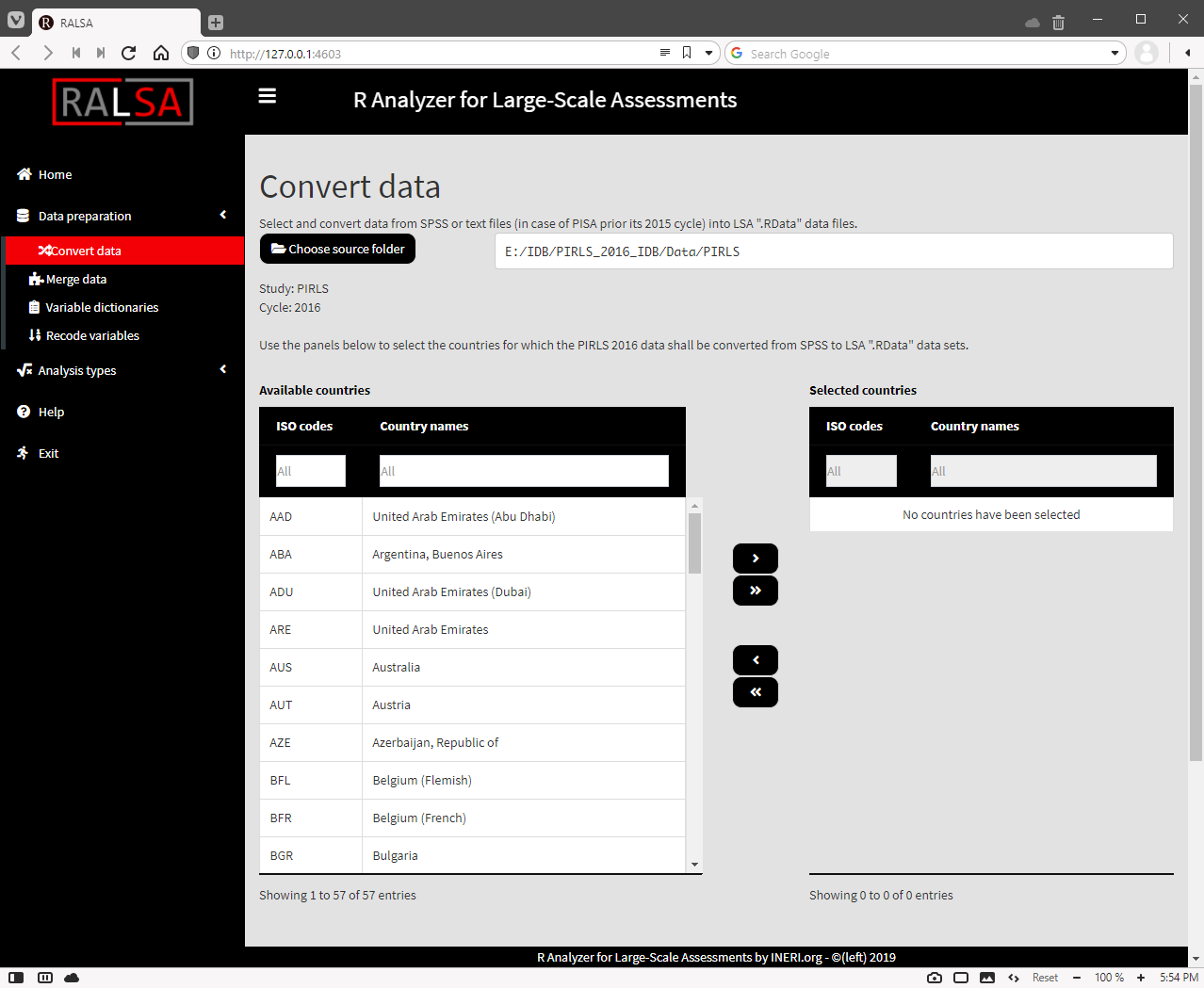
Use the mouse to select and the single and double arrow buttons to move the countries between the lists of Available countries and Selected countries. The single arrow buttons can be used to select and move individual countries between the two panels. The double arrow buttons can be used to move all countries between the two panels, even if none of them are selected. Lets select Australia and Slovenia (again, Slovenia, not Slovakia!). A checkbox and a button will appear underneath. Check the Convert user-defined missings to NA if you want all the SPSS user-defined missing values to be converted to the only supported by R missing value. Otherwise, leave it blank (default), then the SPSS user-defined missing values will be assigned in additional attribute to the variables, later they can be used, if needed. However, if you don’t feel like you will need them, just check the box. Click on the Choose destination folder button and using the folder choose dialog navigate to the folder where you want to save the converted files. After you confirm, the file path to the destination folder, the command syntax field and the syntax execution field will appear at the bottom of the screen:
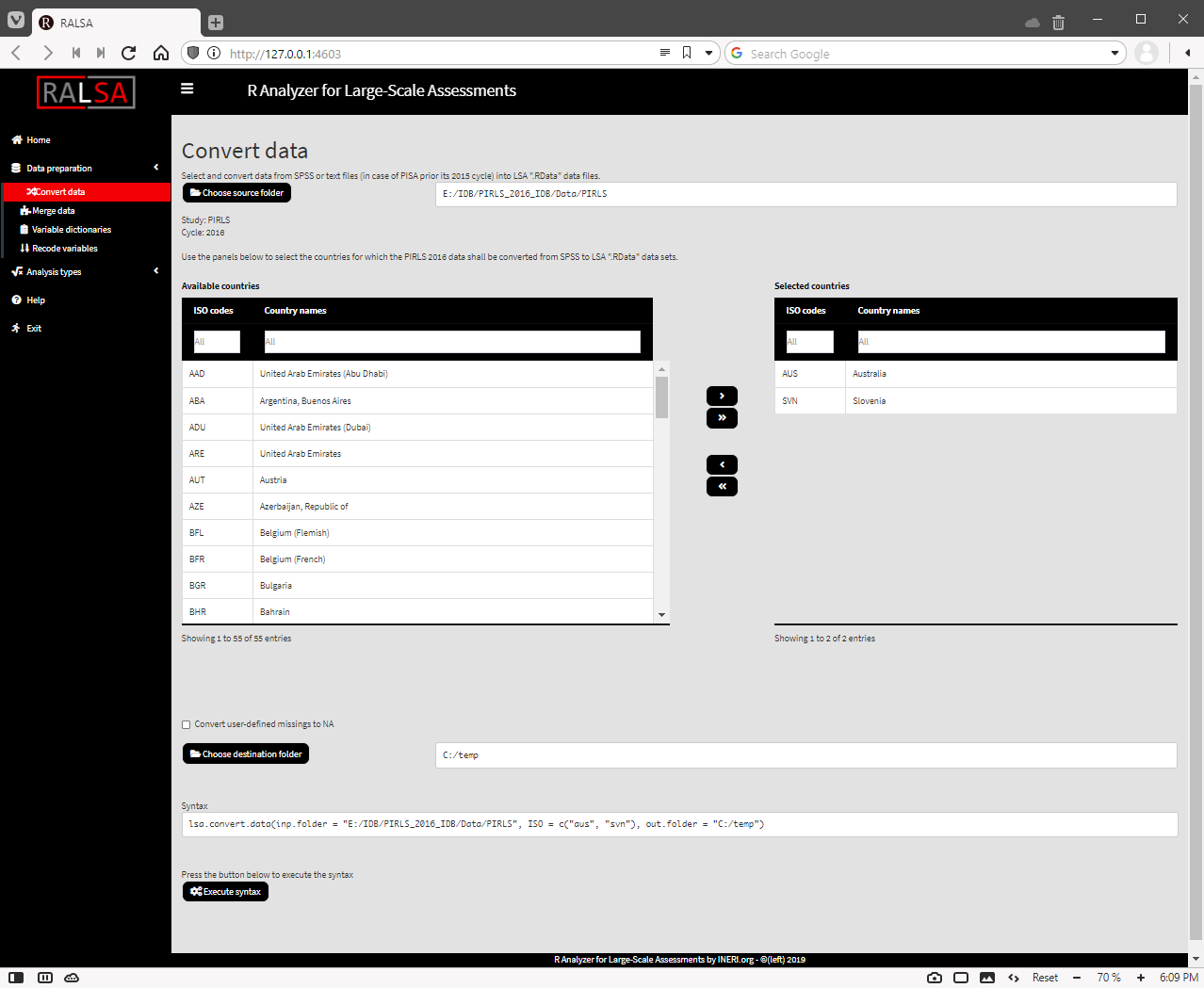
Press the Execute syntax button. A pop-up message will notify you that the file conversion started. A continuously updated console will appear at the bottom of the screen, showing the ongoing operations:
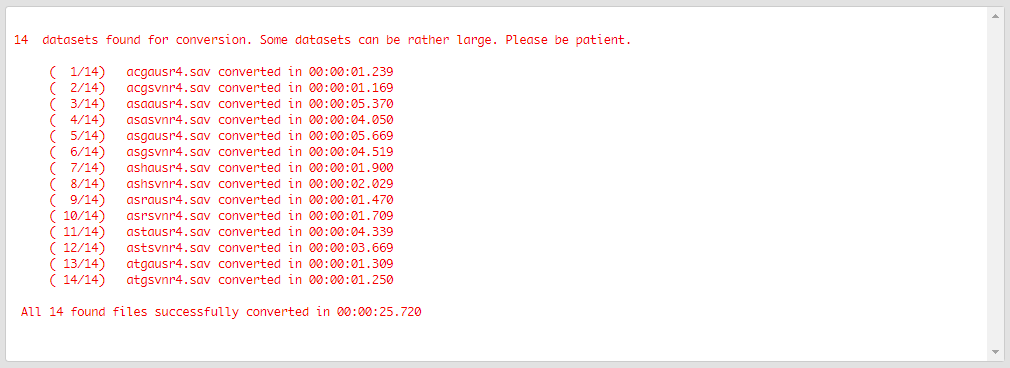
Scroll down if you don’t see it. When all operations are finished, a pop-up message will be shown on the screen notifying you about it.
To convert SPSS files from PISA 2015 and later cycles, follow the exact same steps from above. You won’t be able to select countries or individual files for reasons explained in the previous section. The interface will just show a table with all files available in the folder, the Convert user-defined missings to NA checkbox and the Execute syntax button:
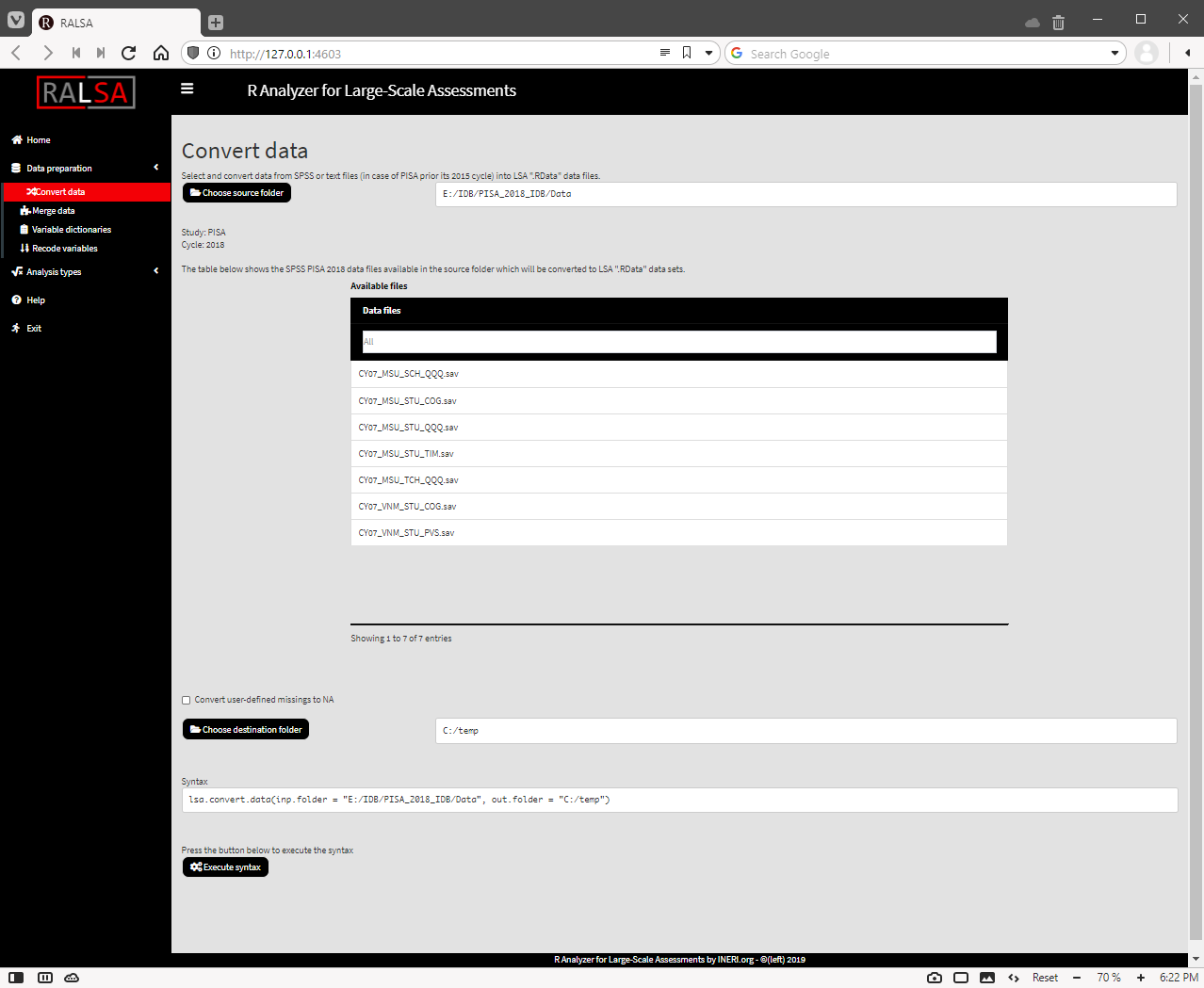
Click on the Execute syntax button. The conversion can take rather long time due to the PISA large file sizes.
Convert PISA 2012 and earlier TXT files
As noted earlier, this option applies only for PISA data prior its 2015 cycle (2000, 2003, 2006, 2009, 2012). These data were provided in TXT files plus SPSS and SAS control syntaxes to import them into SPSS or SAS respectively and save them in their file formats. The lsa.convert.data function uses the TXT files and the corresponding SPSS syntaxes to convert the data into native .RData format. It is important to note that you should download the TXT files and their corresponding SPSS syntaxes from the OECD website (see the link to it here), unpack them from the ZIP files and place them in the same folder without changing them (no changes in the file names or their content). Here we will give examples with the PISA 2012 data.
Converting TXT files using command line
The routine for converting the PISA data from cycles prior to 2015 is the same as for the SPSS files. The only difference is that you would need to add explicitly PISApre15 = TRUE to the call arguments, so that the function shall look for TXT and SPS control syntaxes. Here is an example:
lsa.convert.data(inp.folder = "E:/IDB/PISA_2012_IDB/Data/TXT_Data_Files",
PISApre15 = TRUE, out.folder = "C:/temp")
As with the SPSS files, when converting the TXT files the function will print messages on screen when the conversion of a given file is done. If the function finds SPSS syntaxes and TXT files without corresponding counterparts, it will convert the rest for which pairs are found and will drop a warning when done. The converted files will be located under the out.folder.
As noted earlier, PISA files contain all countries’ data per respondent type. However, an analysis may not need to involve all countries. RALSA has the functionality to load a PISA file, select only the countries needed and save the resulting data under new file. This can be done by the lsa.select.countries.PISA function. Executing the following syntax will take a converted PISA file containing data from all countries participating in the 2021 cycle, select only data from Australia and Slovenia and will save the data from these two countries in a new folder.
lsa.select.countries.PISA(data.file = "C:/temp/pisa2012_spss_student.RData",
cnt.names = c("Australia", "Slovenia"),
output.file = "C:/temp/Selected/pisa2012_spss_student.RData")
Converting TXT files using the GUI
The routine for converting TXT files using the GUI is the same as for converting PISA 2015 and later SPSS files. Select Data preparation > Convert data from the menu on the left. When navigated to the Convert data section in the GUI, click on the Choose source folder. You won’t be able to select countries or individual files for reasons explained in the previous section. The interface will just show a table with all files TXT and their corresponding control SPSS files available in the folder, the Convert user-defined missings to NA checkbox and the Execute syntax button:
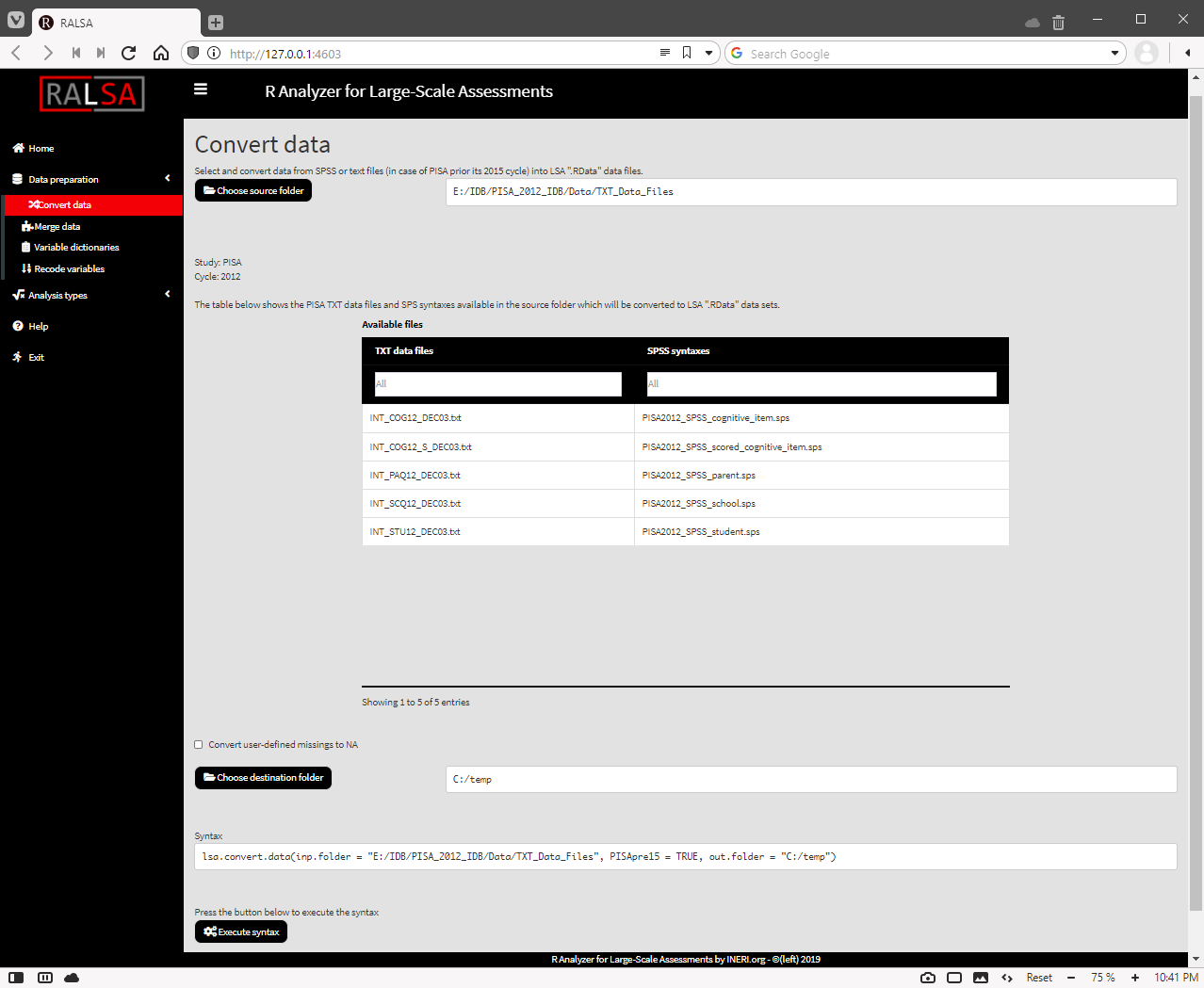
Press the Execute syntax button. The syntax will be executed and all the operations will be displayed in the console window at the bottom of the screen. It will be updated on every step. Note that the TXT files for PISA prior its 2015 cycle are rather large because they contain data from all countries together for every file type and the conversion can take quite long time.
As noted earlier, PISA files contain all countries’ data per respondent type. However, an analysis may not need to involve all countries. RALSA has the functionality to load a PISA file, select only the countries needed and save the resulting data under new file. To do this, navigate to Data preparation -> Select PISA countries. Load a converted PISA file. The GUI will show a list of Available countries on the left. Select the countries you are interested in and use the right arrow button to move them in the list of Selected countries.
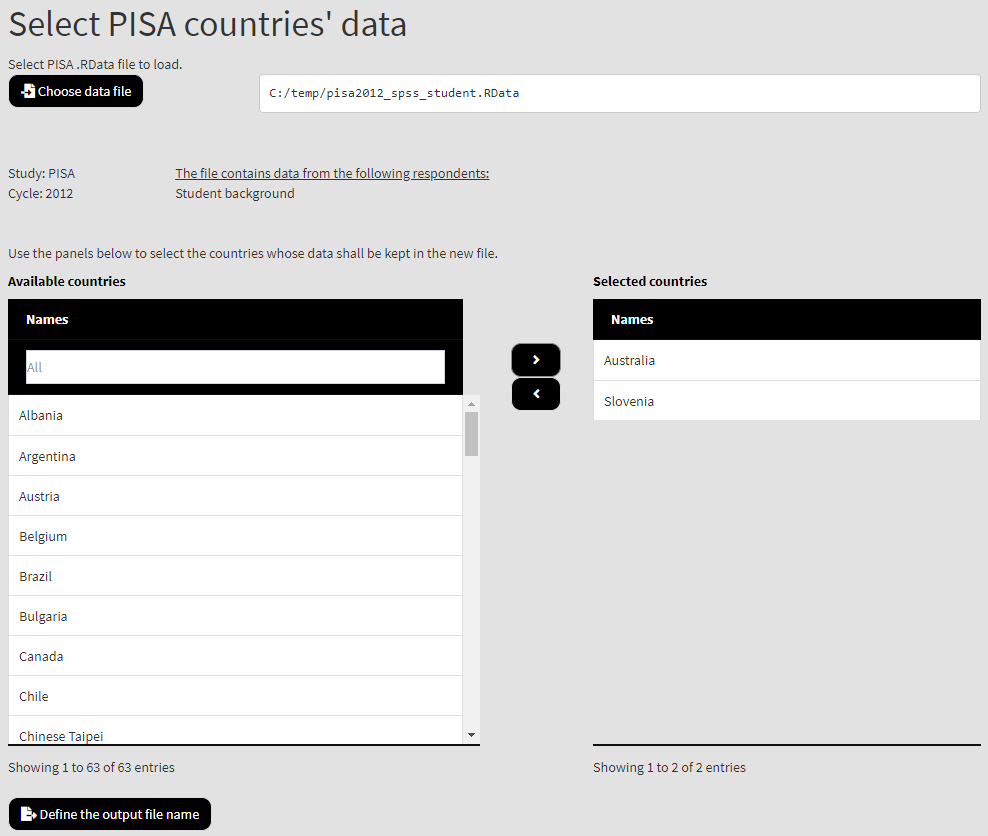
Click on Define the output file name button, navigate to the desired folder and type the name of the file under the PISA data for the selected countries of interest will be saved. The GUI will display an Execute syntax button. Pressing it will perform all operations. After the file is saved, the GUI will show you a message that all operations were completed.