
Table of contents
- Introduction
- The percentiles function and its arguments
- Computing percentiles using the command line
- Computing percentiles using the GUI
Introduction
The lsa.prctls function computes percentiles for continuous variables. The percentiles are the score points corresponding to a given proportion of the distribution of scores in the continuous variable. The percentiles can be computed within groups defined by the categories of splitting variables. The splitting variables are optional. If no splitting variables are provided, the results will be computed on country level only. If splitting variables are provided, the data within each country will be split into groups by all splitting variables and the percentiles for the continuous variables will be computed for the last splitting variable. Note that the percentiles can be computed for both background/contextual variables or sets of PVs, taking into account the complex sampling and assessment design of the study of interest. In the latter case, the percentiles will be computed for each PV in a set, and then the estimates for all PVs in the set will be averaged and their standard error computed using complex formulas which will depend on the study of interest. The standard error will be computed taking into account the complex sample and assessment designs of the studies. Refer here for a short overview on the complex sampling and assessment designs of large-scale assessments and surveys. If interested in more in-depth details on the complex sampling and assessment designs of a particular study and how estimates and their standard errors are computed, refer to its technical documentation and user guide.
Like any other function in the RALSA package, the lsa.prctls function can recognize the study data and apply the correct estimation techniques given the study sampling and assessment design implementation without extra care.
The percentiles function and its arguments
The lsa.prctls function has the following arguments:
data.file– The file containinglsa.dataobject. Either this ordata.objectshall be specified, but not both.data.object– The object in the memory containinglsa.dataobject. Either this ordata.fileshall be specified, but not both.split.vars– Categorical variable(s) to split the results by. If no split variables are provided, the results will be for the overall countries’ populations. If one or more variables are provided, the results will be split by all but the last variable and the percentages of respondents will be computed by the unique values of the last splitting variable.bckg.prctls.vars– Name(s) of continuous background or contextual variable(s) to compute the percentiles for. The results will be computed by all groups specified by the splitting variables.PV.root.prctls– The root name(s) for the set(s) of plausible values.prctls– Vector of integers specifying the percentiles to be computed, the default isc(5, 25, 50, 75, 95).weight.var– The name of the variable containing the weights. If no name of a weight variable is provide, the function will automatically select the default weight variable for the provided data, depending on the respondent type.include.missing– Logical, shall the missing values of the splitting variables be included as categories to split by and all statistics produced for them? The default (FALSE) takes all cases on the splitting variables without missing values before computing any statistics.shortcut– Logical, shall the “shortcut” method for IEA TIMSS, TIMSS Advanced, TIMSS Numeracy, eTIMSS, PIRLS, ePIRLS, PIRLS Literacy and RLII be applied when using PVs? The default (FALSE) applies the “full” design when computing the variance components and the standard errors of the PV estimates.graphs– Logical, shall graphs be produced? Default isFALSE.perc.x.label– String, custom label for the horizontal axis in percentage graphs. Ignored ifgraphs = FALSE.perc.y.label– String, custom label for the vertical axis in percentage graphs. Ignored ifgraphs = FALSE.prctl.x.labels – List of strings, custom labels for the horizontal axis in percentiles’ graphs. Ignored ifgraphs = FALSE.prctl.y.labels– List of strings, custom labels for the vertical axis in percentiles’ graphs. Ignored ifgraphs = FALSE.output.file– Full path to the output file including the file name. If omitted, a file with a default file name “Analysis.xlsx” will be written to the working directory (getwd()).open.output– Logical, shall the output be open after it has been written? The default (TRUE) opens the output in the default spreadsheet program installed on the computer.
Notes:
- Either
data.fileordata.objectshall be provided as source of data. If both of them are provided, the function will stop with an error message. - The function computes percentiles of variables (background/contextual or sets of plausible values) by groups defined by one or more categorical variables (splitting variables). Multiple splitting variables can be added, the function will compute the percentages for all formed groups and their percentiles on the continuous variables. If no splitting variables are added, the results will be computed only by country.
- Multiple continuous background variables can be provided to compute the specified percentiles for them. Please note that in this case the results will slightly differ compared to using each of the same background continuous variables in separate analyses. This is because the cases with the missing values on
bckg.prctls.varsare removed in advance and the more variables are provided tobckg.prctls.vars, the more cases are likely to be removed. - Computation of percentiles involving plausible values requires providing a root of the plausible values names in
PV.root.prctls. All studies (except CivED, TEDS-M, SITES, TALIS and TALIS Starting Strong Survey) have a set of PVs per construct (e.g. in TIMSS five for overall mathematics, five for algebra, five for geometry, etc.). In some studies (say TIMSS and PIRLS) the names of the PVs in a set always start with character string and end with sequential number of the PV. For example, the names of the set of PVs for overall mathematics in TIMSS are BSMMAT01, BSMMAT02, BSMMAT03, BSMMAT04 and BSMMAT05. The root of the PVs for this set to be added toPV.root.prctlswill be “BSMMAT”. The function will automatically find all the variables in this set of PVs and include them in the analysis. In other studies like OECD PISA and IEA ICCS and ICILS the sequential number of each PV is included in the middle of the name. For example, in ICCS the names of the set of PVs are PV1CIV, PV2CIV, PV3CIV, PV4CIV and PV5CIV. The root PV name has to be specified inPV.root.prctlsas “PV#CIV”. More than one set of PVs can be added. Note, however, that providing continuous variable(s) for thebckg.prctls.varsargument and root PV for thePV.root.prctlsargument will affect the results for the PVs because the cases with missing onbckg.prctls.varswill be removed and this will also affect the results from the PVs. On the other hand, using more than one set of PVs at the same time should not affect the results on any PV estimates because PVs shall not have any missing values. - If
include.missing = FALSE(default), all cases with missing values on the splitting variables will be removed and only cases with valid values will be retained in the statistics. Note that the data from the studies can be exported in two different ways using thelsa.convert.data: (1) setting all user-defined missing values to NA; and (2) importing all user-defined missing values as valid ones and adding their codes in an additional attribute to each variable. If theinclude.missinginlsa.prctlsis set toFALSE(default) and the data used is exported using option (2), the output will remove all values from the variable matching the values in itsmissingsattribute. Otherwise, it will include them as valid values and compute statistics for them. - The
shortcutargument is valid only for TIMSS, TIMSS Advanced, TIMSS Numeracy, PIRLS, ePIRLS, PIRLS Literacy and RLII. Previously, in computing the standard errors, these studies were using 75 replicates because one of the schools in the 75 JK zones had its weights doubled and the other one has been taken out. Since TIMSS 2015 and PIRLS 2016 the studies use 150 replicates and in each JK zone once a school has its weights doubled and once taken out, i.e. the computations are done twice for each zone. For more details see the technical documentation and user guides for TIMSS 2015, and PIRLS 2016. If replication of the tables and figures is needed, the shortcut argument has to be changed to TRUE. - If
graphs = TRUE, the function will produce graphs, bar plots for the percentages and line graphs for the percentiles per group defined by thesplit.vars. All plots are produced per country. If nosplit.varsat the end there will be a percentages and error bar plots for all countries together. If needed, custom horizontal and vertical axis labels for the bar plots and line graphs can be defined using theperc.x.label,perc.y.label,prctl.x.labelsandprctl.y.labelsarguments.
If save.output = FALSE, a list containing the estimates and analysis information. If graphs = TRUE, the plots will be added to the list of estimates.
If save.output = TRUE (default), an MS Excel (.xlsx) file (which can be opened in any spreadsheet program), as specified with the full path in the output.file. If the argument is missing, an Excel file with the generic file name “Analysis.xlsx” will be saved in the working directory (getwd()). The workbook contains three spreadsheets. The first one (“Estimates”) contains a table with the results by country and the final part of the table contains averaged results from all countries’ statistics. The following columns can be found in the table, depending on the specification of the analysis:
- <Country ID> – a column containing the names of the countries in the file for which statistics are computed. The exact column header will depend on the country identifier used in the particular study.
- <Split variable 1>, <Split variable 2>… – columns containing the categories by which the statistics were split by. The exact names will depend on the variables in
split.vars. - n_Cases – the number of cases in the sample used to compute the statistics.
- Sum_<Weight variable> – the estimated population number of elements per group after applying the weights. The actual name of the weight variable will depend on the weight variable used in the analysis.
- Sum_<Weight variable>_SE – the standard error of the the estimated population number of elements per group. The actual name of the weight variable will depend on the weight variable used in the analysis.
- Percentages_<Last split variable> – the percentages of respondents (population estimates) per groups defined by the splitting variables in
split.vars. The percentages will be for the last splitting variable which defines the final groups. - Percentages_<Last split variable>_SE – the standard errors of the percentages from above.
- Prctl_<Percentile value>_<Background variable> – the percentile of the continuous <Background variable> specified in
bckg.prctls.vars. There will be one column for each percentile estimate for each variable specified inbckg.prctls.vars. - Prctl_<Percentile value>_<Background variable>_SE – the standard error of the percentile of the continuous <Background variable> specified in
bckg.prctls.vars. There will be one column with the SE per percentile estimate for each variable specified inbckg.prctls.vars. - Percent_Missings_<Background variable> – the percentage of missing values for the <Background variable> specified in
bckg.prctls.vars. There will be one column with the percentage of missing values for each variable specified inbckg.prctls.vars. - Prctl_<Percentile value>_<root PV> – the percentile of the PVs with the same <root PV> specified in
PV.root.prctls. There will be one column per percentile value estimate for each set of PVs specified inPV.root.prctls. - Prctl_<Percentile value>_<root PV>_SE – the standard error per percentile per set of PVs with the same <root PV> specified in
PV.root.prctls. There will be one column with the standard error of estimate per percentile per set of PVs specified inPV.root.prctls. - Prctl_<Percentile value>_<root PV>_SVR – the sampling variance component per percentile per set of PVs with the same <root PV> specified in
PV.root.prctls. There will be one column with the sampling variance component percentile estimate for each set of PVs specified inPV.root.prctls. - Prctl_<Percentile value>_<root PV>_MVR – the measurement variance component per percentiles per set of PVs with the same <root PV> specified in
PV.root.prctls. There will be one column with the measurement variance component per percentile per set of PVs specified inPV.root.prctls. - Percent_Missings_<root PV> – the percentage of missing values for the <root PV> specified in
PV.root.prctls. There will be one column with the percentage of missing values for each set of PVs specified inPV.root.prctls.
The second sheet (“Analysis information”) contains some additional information related to the analysis per country in the following columns:
- DATA – used
data.fileordata.object. - STUDY – which study the data comes from.
- CYCLE – which cycle of the study the data comes from.
- WEIGHT – which weight variable was used.
- DESIGN – which resampling technique was used (JRR or BRR).
- SHORTCUT – logical, whether the shortcut method was used.
- NREPS – how many replication weights were used.
- ANALYSIS_DATE – on which date the analysis was performed.
- START_TIME – at what time the analysis started.
- END_TIME – at what time the analysis finished.
- DURATION – how long the analysis took in hours, minutes, seconds and milliseconds.
The third sheet (“Calling syntax”) contains the call to the function with values for all parameters as it was executed. This is useful if the analysis needs to be replicated later.
If graphs = TRUE there will be an additional “Graphs” sheet containing all plots.
If any warnings resulting from the computations are issued, these will be included in an additional “Warnings” sheet in the workbook as well.
Computing percentiles using the command line
In the examples that follow we will merge a new data file (see how to merge files here) with student and school principal data from PIRLS 2016 (Australia and Slovenia), taking all variables from both file types:
lsa.merge.data(inp.folder = "C:/temp",
file.types = list(acg = NULL, asg = NULL),
ISO = c("aus", "svn"),
out.file = "C:/temp/merged/PIRLS_2016_ACG_ASG_merged.RData")
As a start, let’s compute the 5th, 25th, 50th, 75th, and 95th percentiles of the complex scale on how much students like reading (ASBGSLR, check the PIRLS 2016 technical documentation on how this scale is constructed and its properties) for female and male students in Australia and Slovenia:
lsa.prctls(data.file = "C:/temp/merged/PIRLS_2016_ACG_ASG_merged.RData",
split.vars = "ASBG01", bckg.prctls.vars = "ASBGSLR",
output.file = "C:/temp/Results/PIRLS_2016_Percentiles_by_Student_Sex.xlsx")
Few things to note:
- There are two variables containing the information on student sex:
- ITSEX, a variable containing the student tracking information; and
- ASBG01 (used in this analysis), a variable containing the student sex as the students responded in the questionnaire.
- In international large-scale assessments all analyses must be done separately by country. There is no need, however, to add the country ID variable (IDCNTRY, or CNT in PISA) as a splitting variable. The function will identify it automatically and add it to the the vector of
split.vars. - There is no need to specify the weight variable explicitly. If no weight variable is specified explicitly, then the default weight (total student weight in this case) will be used for the data set depending on the merged respondents’ data, it is identified automatically. If you have a good reason to change the weight variable, you can do so by adding the
weight.var = "SENWGT", for example. - No values were specified for the
prctlsargument. In such case, the function will automatically add the default percentiles asprctls = c(5, 25, 50, 75, 95). If you need a different cut points in the distribution, just add them, following the rules for this argument. - If no output file is specified, then the output will be saved with “Analysis.xlsx” file name under the working directory (can be obtained with
getwd()). - Unless explicitly adding
open.output = FALSE, to the calling syntax, the output file will be opened after all computations are finished. This is useful when multiple calling syntaxes for different analyses are executed and no immediate inspection of the output is needed.
Executing the code from above will print the following output in the RStudio console:
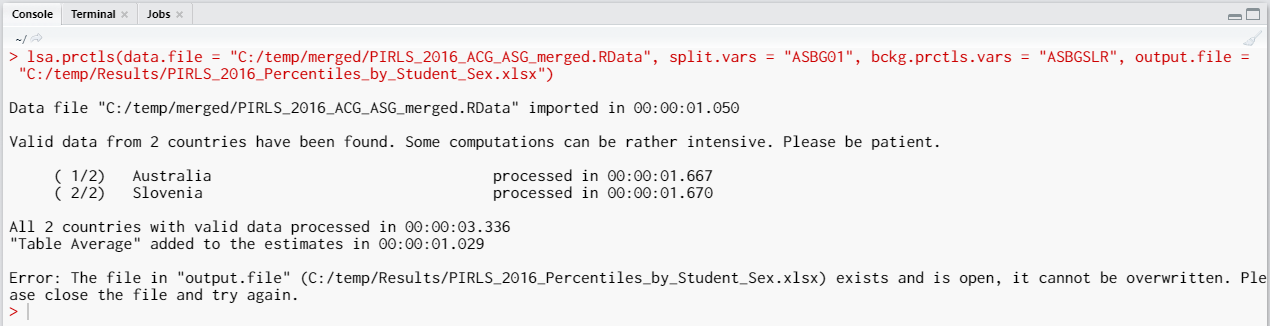
When all operations are finished the output will be written on the disk as MS Excel workbook. If open.output = TRUE (default), the file will be open in the default spreadsheet program (usually MS Excel). Refer to the explanations on the structure of the workbook, its sheets and the columns here.
The function can also compute the mean for a set (or sets) of plausible values. Let’s compute the 25th, 50th, and 75th percentiles of the plausible values for the overall reading achievement for girls and boys. The following syntax does this:
lsa.prctls(data.file = "C:/temp/merged/PIRLS_2016_ACG_ASG_merged.RData",
split.vars = "ASBG01", PV.root.prctls = "ASRREA", prctls = c(25, 50, 75),
output.file = "C:/temp/Results/PIRLS_2016_Percentiles_by_Student_Sex.xlsx")
Note how the PVs are specified. The five PVs for the overall reading achievement are ASRREA01, ASRREA02, ASRREA03, ASRREA04, and ASRREA05. In the PV.root.avg argument we need to specify only the root of the PVs, “ASRREA”. The function will use this root/common name to select all five PVs and include them in the computations. For more details on the PV roots (also for the PV roots for studies other than TIMSS and PIRLS and their additions), the computational routines involving PVS, see here.
Executing the syntax from above will overwrite the previous output because it has the same file name defined (a warning will be displayed in the console). The columns in the “Estimates” sheet will now be different. For the meaning of the column names, refer to the list here.
Computing percentiles using the GUI
To start the RALSA user interface, execute the following command in RStudio:
ralsaGUI()
For the examples that follow, merge a new file with PIRLS 2016 data for Australia and Slovenia (Slovenia, not Slovakia) taking all student and school principal variables. See how to merge data files here. You can name the merged file PIRLS_2016_ACG_ASG_merged.RData.
When done merging the data, select Analysis types > Percentiles from the menu on the left. When navigated to the Percentiles in the GUI, click on the Choose data file button. Navigate to the folder containing the merged PIRLS_2016_ACG_ASG_merged.RData file, select it and click the Select button.
Once the file is loaded, you will see a panel on the left (available variables) and set of panels on the right where variables from the list of available ones can be added.
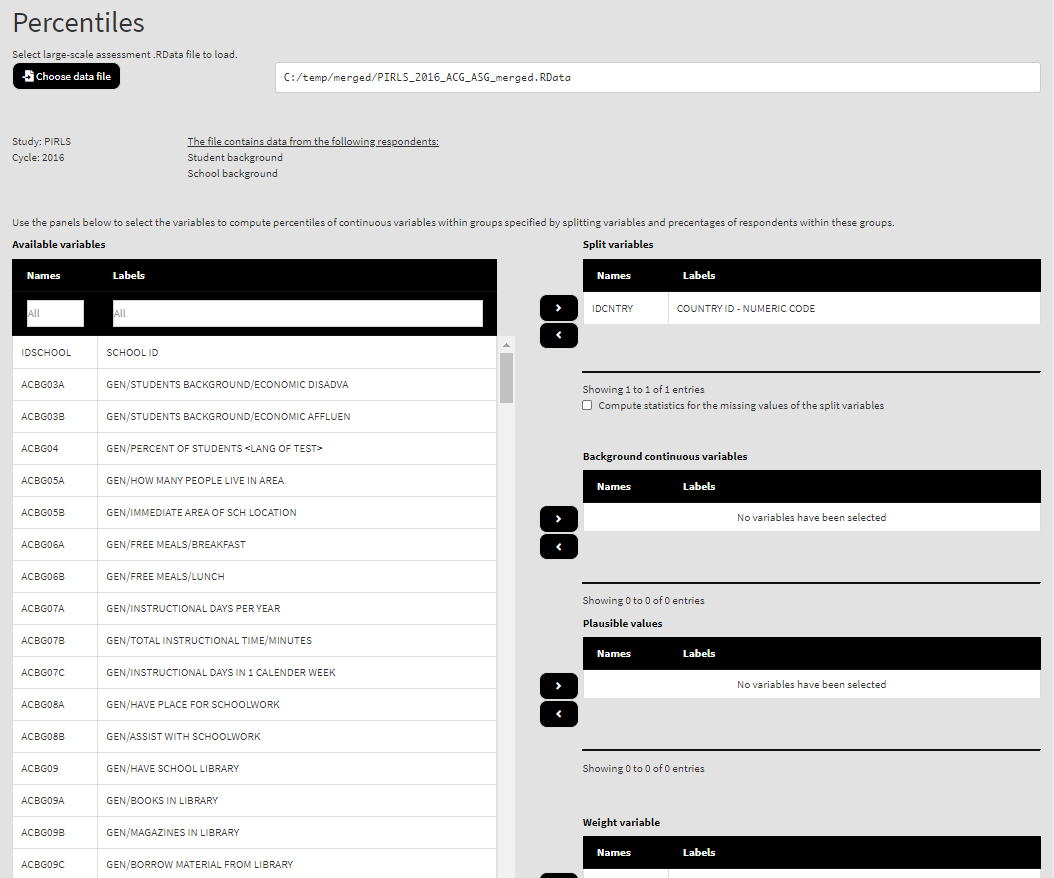
Use the mouse to select variables from the list of Available variables and the arrow buttons in the middle of the screen to add them to different fields (or remove them) to make the settings for the analysis. You can use the filter boxes on the top of the panels to find the needed variables quickly.
As a start, let’s compute the 5th, 25th, 50th, 75th, and 95th percentiles of the complex scale on how much students like reading (ASBGSLR, check the PIRLS 2016 technical documentation on how this scale is constructed and its properties) for female and male students in Australia and Slovenia. Add the variable ASBG01 to the list of Split variables. Locate the variable ASBGSLR in the list of Available variables and use the right arrow button to add it to the Background continuous variables panel. This is all that needs to be done. Underneath the panels you will see a text field with the default percentile values (5, 25, 50, 75, and 95). You can change them to any values, following the instructions above the box, but let’s leave them as they are for now. Next to the box you will see a Reset button. If you have changed the values in the box and want to revert to the default values, simply click it. Scroll down and click on the Define output file name. Navigate to the folder C:/temp/Results (or to the folder where you want to save the output) and define the output file name. After you do so, a checkbox will appear next to the Define the output file name. If ticked, the output will open after all computations are finished. Underneath the calling syntax will be displayed. Under all of these the Execute syntax button will be displayed. The final settings in the lower part of the screen should look like this:
Click on the Execute syntax button. The GUI console will appear at the bottom and will log all completed operations:
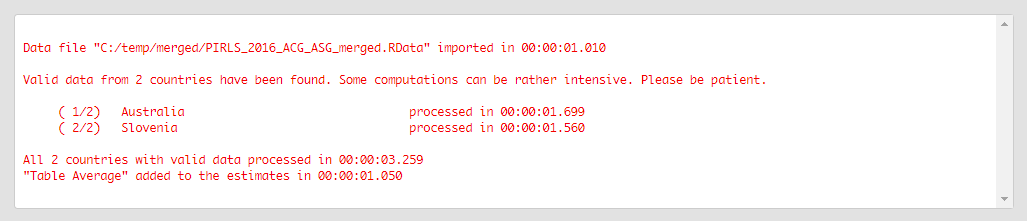
Few things to note:
- There are two variables containing the information on student sex:
- ITSEX, a variable containing the student tracking information; and
- ASBG01 (used in this analysis), a variable containing the student sex as the students responded in the questionnaire.
- In international large-scale assessments all analyses must be done separately by country. The country ID variable (IDCNTRY, or CNT in PISA) is always selected as the first splitting variable and cannot be removed from the Split variables panel.
- The default weight variable is selected and added automatically in the Weight variable panel. It can be changed with another weight variable available in the data set. If the default weight variable is selected, it will not be shown in the syntax window. If no weight variable is selected in the Weight variable panel, the default one will be used automatically.
- The Use shortcut method for computing SE checkbox is not ticked by default. This will make the function to compute the standard error using the “full” method for the sampling variance component. For more details see here and here.
If the Open the output when done checkbox is ticked, the output will open automatically in the default spreadsheet program (usually MS Excel) when all computations are completed. Refer to the explanations on the structure of the workbook, its sheets and the columns here.
The function can also compute the mean for a set (or sets) of plausible values. Let’s compute the 25th, 50th, and 75th percentiles of the plausible values for the overall reading achievement for girls and boys. To continue, remove the ASBGSLR variable from the Background continuous variables panel. From the list of Available variables locate the root of the overall reading plausible values (ASRREA). You can use the filter boxes at the top of the panel to search for it, either by name or label. Select the root and add it to the Plausible values panel using the arrow buttons. This section of the interface should look like this:
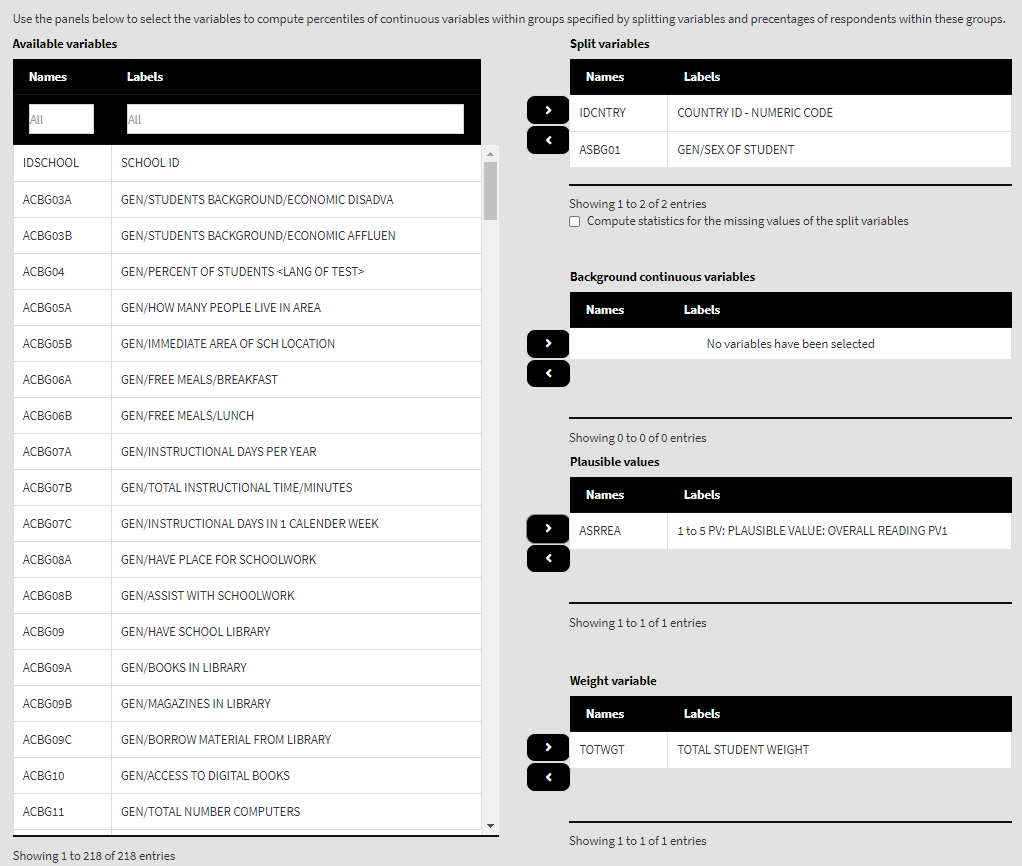
Note how the PVs are specified. The five PVs for the overall reading achievement are ASRREA01, ASRREA02, ASRREA03, ASRREA04, and ASRREA05. The lists of Available variables and Plausible values will not show the five separate PVs, but just their root/common name – ASRREA, without the numbers at the end. In the background, the function will take all the five PVs and include them in the computations. For more details on the PV roots (also for the PV roots for studies other than TIMSS and PIRLS and their additions), the computational routines involving PVS, see here.
We need to change the percentile values in the box in the interface because we don’t want to use the default ones. Simply click in the box and leave only 25, 50 and 75, delete the rest. You can also type the values by hand. After changing the values, the box should look like this:

Because we use the application with Percentiles directly after performing the previous analysis, we still have the rest of the settings from the previous analysis done. There is no need to change any of the remaining settings, unless you want to. You could, though, change the output file name, otherwise it will be overwritten. Note that the displayed syntax will change, reflecting the inclusion of the root of the five PVs, ASRREA, for the overall reading achievement to compute the mean for:
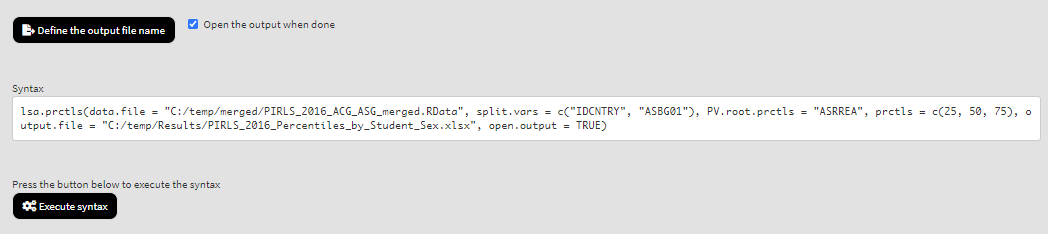
Press the Execute syntax button. The GUI console will update, logging all completed operations:
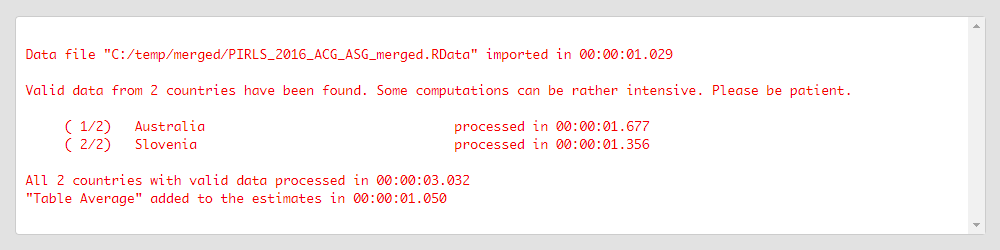
After all computations are completed, the output will open automatically.